Wide Research: Beyond the Context Window
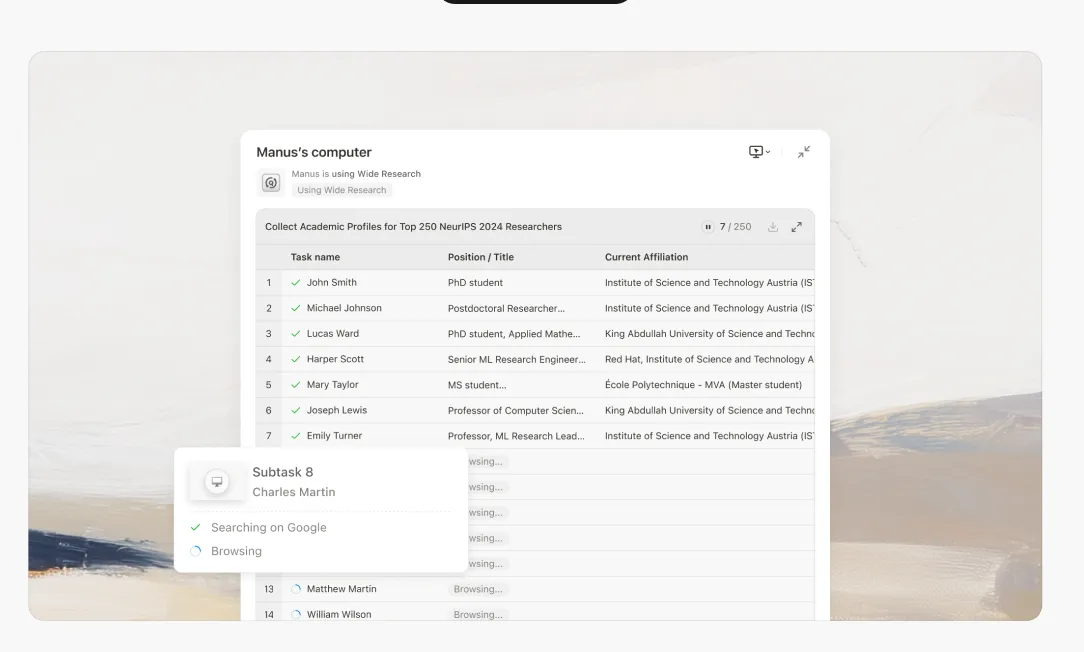
คำสัญญาของการวิจัยที่ขับเคลื่อนด้วย AI นั้นมีความน่าสนใจเสมอ: มอบหมายงานที่น่าเบื่อของการรวบรวมข้อมูลและการสังเคราะห์ให้กับระบบอัจฉริยะ เพื่อปลดปล่อยการรับรู้ของมนุษย์สำหรับการวิเคราะห์ระดับสูงและการตัดสินใจ อย่างไรก็ตาม ทุกคนที่ผลักดันระบบเหล่านี้ในกรณีการใช้งานที่ไม่ธรรมดาได้พบกับความเป็นจริงที่น่าหงุดหงิด: เมื่อถึงรายการที่แปดหรือเก้าในงานวิจัยหลายหัวข้อ AI เริ่มสร้างข้อมูลเท็จ
ไม่ใช่แค่การทำให้ง่ายขึ้น ไม่ใช่แค่การสรุปให้กระชับขึ้น แต่เป็นการสร้างข้อมูลเท็จ
นี่ไม่ใช่ปัญหาของการออกแบบคำสั่ง ไม่ใช่ปัญหาความสามารถของโมเดล แต่เป็นข้อจำกัดทางสถาปัตยกรรมที่จำกัดประโยชน์ของเครื่องมือวิจัย AI อย่างเงียบๆ ตั้งแต่เริ่มต้น และนี่คือข้อจำกัดที่ Wide Research ถูกออกแบบมาเพื่อเอาชนะ
หน้าต่างบริบท: คอขวดพื้นฐาน
ภาษาโมเดลขนาดใหญ่ทุกตัวทำงานภายในหน้าต่างบริบท ซึ่งเป็นบัฟเฟอร์หน่วยความจำที่จำกัดปริมาณข้อมูลที่โมเดลสามารถประมวลผลได้อย่างกระตือรือร้นในขณะใดขณะหนึ่ง โมเดลสมัยใหม่ได้ผลักดันขอบเขตนี้อย่างน่าประทับใจ: จาก 4K โทเค็นไปถึง 32K, 128K และแม้กระทั่ง 1M โทเค็นในเวอร์ชันล่าสุด
แต่ปัญหายังคงอยู่
เมื่อคุณขอให้ AI วิจัยเอนทิตีหลายรายการ - สมมติว่า ห้าสิบบริษัท สามสิบงานวิจัย หรือยี่สิบผลิตภัณฑ์ที่แข่งขันกัน - หน้าต่างบริบทจะเต็มอย่างรวดเร็ว ไม่ใช่แค่ข้อมูลดิบเกี่ยวกับแต่ละเอนทิตี แต่ยังรวมถึง:
•ข้อกำหนดงานและข้อกำหนดเฉพาะเดิม
•เทมเพลตโครงสร้างสำหรับการจัดรูปแบบผลลัพธ์ที่สอดคล้องกัน
•การให้เหตุผลและการวิเคราะห์ขั้นกลางสำหรับแต่ละรายการ
•การอ้างอิงข้าม และบันทึกเปรียบเทียบ
•บริบทสะสมของรายการก่อนหน้าทั้งหมด
เมื่อโมเดลถึงรายการที่แปดหรือเก้า หน้าต่างบริบทจะอยู่ภายใต้ความตึงเครียดอย่างมาก โมเดลเผชิญกับทางเลือกที่เป็นไปไม่ได้: ล้มเหลวอย่างชัดเจน หรือเริ่มลดความสำคัญบางส่วนมันเลือกอย่างหลังเสมอ
เกณฑ์การสร้างเรื่อง
นี่คือสิ่งที่เกิดขึ้นในทางปฏิบัติ:
รายการ 1-5: โมเดลทำการวิจัยที่แท้จริง มันดึงข้อมูล อ้างอิงแหล่งที่มา และสร้างการวิเคราะห์ที่ละเอียดและถูกต้อง
รายการ 6-8: คุณภาพเริ่มเสื่อมลงอย่างแยบยล คำอธิบายเริ่มกลายเป็นแบบทั่วไปมากขึ้น โมเดลเริ่มพึ่งพารูปแบบก่อนหน้ามากกว่าการวิจัยใหม่
รายการ 9+: โมเดลเข้าสู่โหมดการสร้างเรื่อง ไม่สามารถรักษาภาระทางความคิดของการวิจัยอย่างละเอียดในขณะที่จัดการกับบริบทที่ล้นเกิน มันเริ่มสร้างเนื้อหาที่ฟังดูน่าเชื่อถือโดยอิงจากรูปแบบทางสถิติ ไม่ใช่การสืบค้นจริง
การสร้างเรื่องเหล่านี้มีความซับซ้อน พวกมันฟังดูน่าเชื่อถือ ทำตามรูปแบบที่กำหนดไว้อย่างสมบูรณ์แบบ มักจะถูกต้องตามหลักไวยากรณ์อย่างสมบูรณ์และมีรูปแบบที่สอดคล้องกับรายการก่อนหน้าที่ถูกต้อง
พวกมันมักจะผิดด้วยการวิเคราะห์คู่แข่งอาจระบุคุณสมบัติให้กับบริษัทที่ไม่ได้นำเสนอคุณสมบัตินั้น การทบทวนวรรณกรรมอาจอ้างอิงงานวิจัยที่มีผลการค้นพบที่ถูกแต่งขึ้น การเปรียบเทียบผลิตภัณฑ์อาจสร้างระดับราคาหรือข้อกำหนดที่ไม่มีอยู่จริง
ส่วนที่อันตรายคือการแต่งเรื่องเหล่านี้ยากที่จะตรวจจับได้โดยไม่มีการตรวจสอบด้วยตนเอง—ซึ่งทำให้วัตถุประสงค์ทั้งหมดของการวิจัยอัตโนมัติไร้ประโยชน์
ทำไมหน้าต่างบริบทที่ใหญ่ขึ้นไม่สามารถแก้ไขปัญหานี้ได้
คำตอบที่เข้าใจง่ายคือการขยายหน้าต่างบริบท หาก 32K โทเค็นไม่เพียงพอ ให้ใช้ 128K หากยังไม่พอ ก็ผลักดันไปถึง 200K หรือมากกว่านั้น
แนวทางนี้เข้าใจปัญหาผิด
ประการแรก การเสื่อมของบริบทไม่ใช่แบบไบนารี โมเดลไม่ได้รักษาความจำที่สมบูรณ์แบบตลอดทั้งหน้าต่างบริบท การศึกษาแสดงให้เห็นว่าความแม่นยำในการดึงข้อมูลลดลงตามระยะห่างจากตำแหน่งปัจจุบัน—ปรากฏการณ์ "หลงในตรงกลาง" ข้อมูลที่อยู่ตอนเริ่มต้นและตอนท้ายของบริบทถูกจดจำได้อย่างน่าเชื่อถือมากกว่าข้อมูลที่อยู่ตรงกลางประการที่สอง ต้นทุนการประมวลผลเพิ่มขึ้นอย่างไม่สมดุล ต้นทุนในการประมวลผลบริบทขนาด 400K โทเค็นไม่ได้เพียงแค่เป็นสองเท่าของต้นทุนที่ใช้กับ 200K—แต่มันเพิ่มขึ้นแบบเอกซ์โพเนนเชียลทั้งในด้านเวลาและทรัพยากรการคำนวณ สิ่งนี้ทำให้การประมวลผลบริบทขนาดใหญ่ไม่คุ้มค่าทางเศรษฐกิจสำหรับการใช้งานหลายกรณี
ประการที่สาม ปัญหาคือภาระทางความคิด แม้จะมีบริบทไม่จำกัด การขอให้โมเดลเดียวรักษาคุณภาพที่สม่ำเสมอในงานวิจัยอิสระหลายสิบรายการสร้างคอขวดทางความคิด โมเดลต้องสลับบริบทระหว่างรายการต่างๆ อยู่ตลอดเวลา รักษากรอบการเปรียบเทียบ และรับประกันความสอดคล้องด้านสไตล์—ทั้งหมดนี้ในขณะที่กำลังทำงานวิจัยหลักประการที่สี่ แรงกดดันจากความยาวบริบท "ความอดทน" ของโมเดลถูกกำหนดในระดับหนึ่งโดยการกระจายความยาวของตัวอย่างในข้อมูลฝึกฝน อย่างไรก็ตาม การผสมข้อมูลหลังการฝึกฝนของโมเดลภาษาปัจจุบันยังคงถูกครอบงำโดยเส้นทางที่ค่อนข้างสั้นซึ่งออกแบบมาสำหรับการโต้ตอบแบบแชทบอท ผลที่ตามมาคือ เมื่อความยาวของเนื้อหาข้อความของผู้ช่วยเกินเกณฑ์หนึ่ง โมเดลจะเผชิญกับแรงกดดันด้านความยาวบริบทโดยธรรมชาติ ทำให้เร่งสรุปหรือใช้รูปแบบการแสดงออกที่ไม่สมบูรณ์เช่นการใช้สัญลักษณ์หัวข้อย่อย
หน้าต่างบริบทเป็นข้อจำกัด ใช่ แต่มันเป็นอาการของข้อจำกัดทางสถาปัตยกรรมที่ลึกกว่านั้น: กระบวนทัศน์แบบตัวประมวลผลเดียว แบบลำดับ
การเปลี่ยนแปลงทางสถาปัตยกรรม: การประมวลผลแบบขนาน
Wide Research ไม่ใช่แค่การคิดใหม่เกี่ยวกับวิธีที่ระบบ AI ควรจะจัดการกับงานวิจัยขนาดใหญ่ แทนที่จะให้ตัวประมวลผลหนึ่งตัวจัดการกับ n รายการอย่างต่อเนื่อง เราใช้ n ตัวแทนย่อยที่ทำงานแบบขนานเพื่อประมวลผล n รายการพร้อมกัน
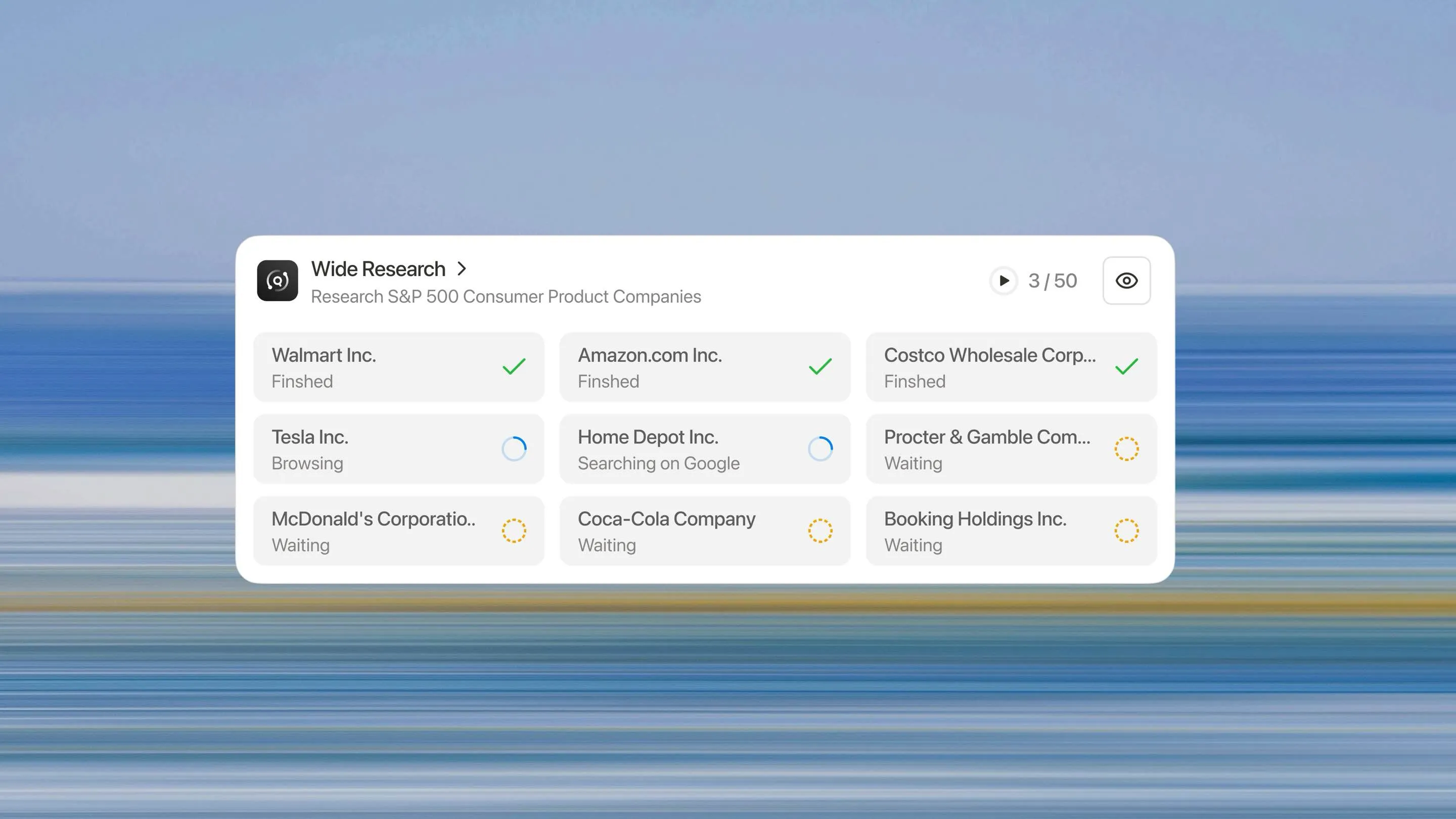
สถาปัตยกรรม Wide Research
เมื่อคุณเริ่มงาน Wide Research ระบบจะทำงานดังนี้:
1. การแยกส่วนอย่างชาญฉลาด
ตัวควบคุมหลักจะวิเคราะห์คำขอของคุณและแบ่งเป็นงานย่อยที่เป็นอิสระและทำงานแบบขนานได้ ซึ่งเกี่ยวข้องกับการทำความเข้าใจโครงสร้างงาน การระบุความสัมพันธ์ และการสร้างข้อกำหนดย่อยที่สอดคล้องกัน
2. การมอบหมายให้ตัวแทนย่อย
สำหรับแต่ละงานย่อย ระบบจะเรียกใช้ตัวแทนย่อยเฉพาะ สิ่งสำคัญคือสิ่งเหล่านี้ไม่ใช่กระบวนการเบา—แต่เป็นอินสแตนซ์ Manus ที่มีคุณสมบัติครบถ้วน แต่ละตัวมี:
•สภาพแวดล้อมเครื่องเสมือนที่สมบูรณ์
•การเข้าถึงห้องสมุดเครื่องมือทั้งหมด (การค้นหา, การเรียกดู, การเรียกใช้โค้ด, การจัดการไฟล์)
•การเชื่อมต่ออินเทอร์เน็ตอิสระ
•หน้าต่างบริบทใหม่ที่ว่างเปล่า
3. การทำงานแบบขนาน
ตัวแทนย่อยทั้งหมดทำงานพร้อมกัน แต่ละตัวมุ่งเน้นเฉพาะรายการที่ได้รับมอบหมาย โดยทำการวิจัยและวิเคราะห์ในระดับความลึกเดียวกันกับที่จะทำสำหรับงานที่มีรายการเดียว
4. การประสานงานแบบรวมศูนย์
ตัวควบคุมหลักคงการกำกับดูแล รวบรวมผลลัพธ์เมื่อตัวแทนย่อยทำงานเสร็จสิ้น สิ่งสำคัญคือ ตัวแทนย่อยไม่ได้สื่อสารระหว่างกัน การประสานงานทั้งหมดผ่านตัวควบคุมหลัก ซึ่งป้องกันการปนเปื้อนของบริบทและรักษาความเป็นอิสระ
5. การสังเคราะห์และการบูรณาการ
เมื่อตัวแทนย่อยทั้งหมดรายงานผลกลับมาแล้ว ตัวควบคุมหลักจะสังเคราะห์ผลลัพธ์เป็นรายงานเดียวที่สอดคล้อง เป็นเอกภาพ และครอบคลุม ขั้นตอนการสังเคราะห์นี้ใช้ประโยชน์จากความสามารถในการจัดการบริบทเต็มรูปแบบของตัวควบคุมหลัก เนื่องจากไม่ต้องแบกรับภาระในการวิจัยเบื้องต้น
ทำไมสิ่งนี้จึงเปลี่ยนแปลงทุกสิ่ง
คุณภาพที่คงที่ในระดับขยาย
ทุกรายการได้รับการจัดการเหมือนกัน รายการที่ 50 ได้รับการวิจัยอย่างละเอียดเท่ากับรายการแรก ไม่มีเส้นโค้งของการเสื่อมคุณภาพ ไม่มีขีดจำกัดของการสร้างข้อมูลเท็จ และไม่มีจุดตกของคุณภาพ
ความสามารถในการขยายตัวแนวนอนอย่างแท้จริง
ต้องการวิเคราะห์ 10 รายการ? ระบบจะใช้งาน sub-agent 10 ตัว ต้องการวิเคราะห์ 500 รายการ? ระบบจะใช้งาน 500 ตัว สถาปัตยกรรมนี้ขยายตัวแบบเชิงเส้นตามขนาดของงาน ไม่ใช่แบบเอกซ์โพเนนเชียลเหมือนวิธีการที่อิงกับบริบท
เพิ่มความเร็วอย่างมีนัยสำคัญ
เนื่องจาก sub-agent ทำงานแบบขนาน เวลาในโลกจริงที่ต้องใช้ในการวิเคราะห์ 50 รายการจึงใกล้เคียงกับเวลาที่ใช้วิเคราะห์ 5 รายการ คอขวดเปลี่ยนจากเวลาการประมวลผลแบบลำดับไปเป็นเวลาการสังเคราะห์—ซึ่งเป็นส่วนประกอบที่เล็กกว่ามากของงานโดยรวม
ลดอัตราการสร้างข้อมูลเท็จ
ความเป็นอิสระและความน่าเชื่อถือ
เนื่องจากตัวแทนย่อยไม่ได้แชร์บริบทร่วมกัน ข้อผิดพลาดหรือการเข้าใจผิดในงานของตัวแทนย่อยหนึ่งจะไม่แพร่กระจายไปยังตัวอื่นๆ การวิเคราะห์แต่ละอย่างเป็นอิสระจากกัน ซึ่งช่วยลดความเสี่ยงเชิงระบบ
เกินกว่าแนวคิดโปรเซสเซอร์เดี่ยว
Wide Research เป็นมากกว่าฟีเจอร์—มันเป็นตัวแทนของการเปลี่ยนแปลงพื้นฐานจากแนวคิดโปรเซสเซอร์เดี่ยวไปสู่สถาปัตยกรรมแบบขนานที่มีการจัดระเบียบ อนาคตของระบบ AI ไม่ได้อยู่ที่หน้าต่างบริบทที่ใหญ่ขึ้นเรื่อยๆ แต่อยู่ที่การแยกงานอย่างชาญฉลาดและการทำงานแบบขนาน
เรากำลังเคลื่อนจากยุคของ "ผู้ช่วย AI" ไปสู่ยุคของ "แรงงาน AI"เมื่อใดควรใช้ Wide Research: งานใดๆ ที่เกี่ยวข้องกับรายการที่คล้ายกันหลายรายการที่ต้องการการวิเคราะห์ที่สม่ำเสมอ เช่น การวิจัยคู่แข่ง การทบทวนวรรณกรรม การประมวลผลจำนวนมาก การสร้างสินทรัพย์หลายชิ้น
เมื่อใดไม่ควรใช้: งานที่มีลำดับขั้นตอนอย่างลึกซึ้งซึ่งแต่ละขั้นตอนขึ้นอยู่กับผลลัพธ์ก่อนหน้าอย่างมาก หรืองานขนาดเล็ก (น้อยกว่า 10 รายการ) ซึ่งการจัดการด้วยโปรเซสเซอร์เดียวมีความคุ้มค่ามากกว่า
Wide Research มีไว้สำหรับผู้สมัครสมาชิกทุกคน
การก้าวกระโดดทางสถาปัตยกรรมจากผู้ช่วย AI เพียงรายเดียวไปสู่ทีมงานที่ประสานงานกันของตัวแทนย่อยนั้นมีให้บริการแก่ผู้สมัครสมาชิกทุกคนแล้ว นี่คือกระบวนทัศน์ใหม่สำหรับการวิจัยและการวิเคราะห์ที่ขับเคลื่อนด้วย AI
เราขอเชิญคุณมาสัมผัสความแตกต่างด้วยตัวคุณเอง นำความท้าทายในการวิจัยขนาดใหญ่ของคุณ—สิ่งที่คุณคิดว่าเป็นไปไม่ได้สำหรับ AI—และเห็นว่าวิธีการประมวลผลแบบขนานสามารถส่งมอบผลลัพธ์ที่สม่ำเสมอและมีคุณภาพสูงในระดับที่กว้างขึ้นได้อย่างไร
ยุคของกำลังแรงงาน AI มาถึงแล้ว เริ่มงาน Wide Research ของคุณวันนี้ลองใช้ Manus Wide Research ใน Manus Pro →
