와이드 리서치: 컨텍스트 윈도우를 넘어서
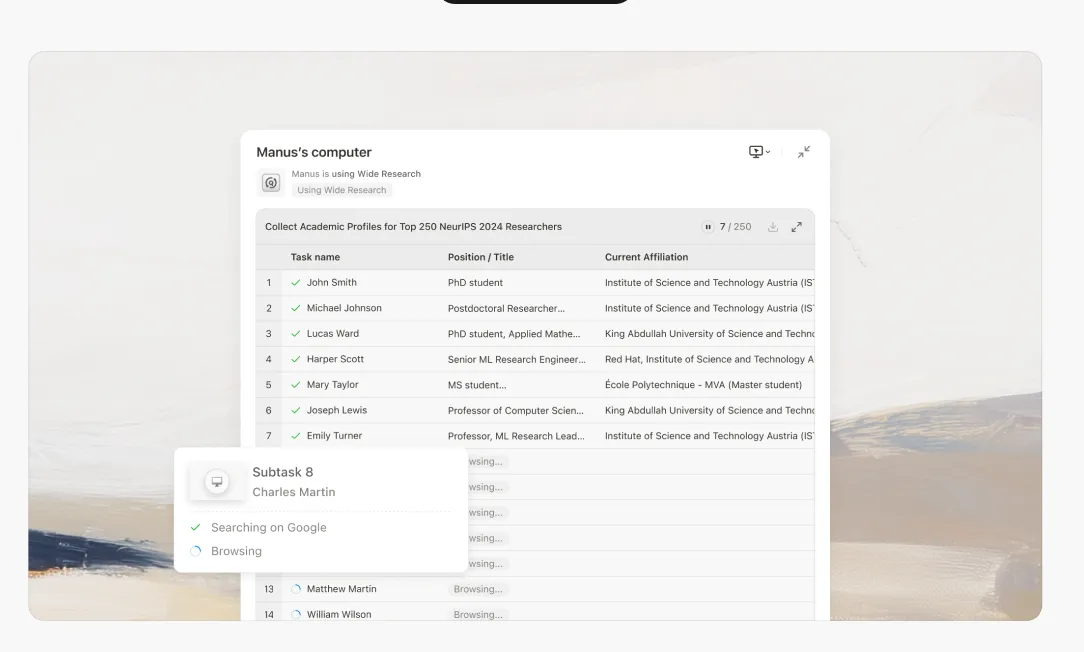
AI 기반 연구의 약속은 항상 매력적이었습니다: 정보 수집과 합성이라는 지루한 작업을 지능형 시스템에 위임하여 인간의 인지를 더 높은 차원의 분석과 의사결정에 집중할 수 있게 하는 것입니다. 그러나 이러한 시스템을 복잡한 사용 사례에 적용해 본 사람이라면 누구나 답답한 현실에 직면했을 것입니다: 여러 주제의 연구 작업에서 8번째나 9번째 항목쯤 되면 AI가 정보를 날조하기 시작합니다.
단순히 단순화하는 것이 아닙니다. 단지 더 간결하게 요약하는 것이 아닙니다. 날조하는 것입니다.
이것은 프롬프트 엔지니어링 문제가 아닙니다. 모델 능력의 문제도 아닙니다. 이는 AI 연구 도구의 유용성을 그 시작부터 조용히 제한해 온 구조적 제약입니다. 그리고 이것이 바로 Wide Research가 극복하도록 설계된 제약입니다.
컨텍스트 윈도우: 근본적인 병목 현상
모든 대형 언어 모델은 컨텍스트 윈도우 내에서 작동하며, 이는 모델이 어느 순간에도 활발하게 처리할 수 있는 정보의 양을 제한하는 유한한 메모리 버퍼입니다. 현대 모델들은 이 경계를 인상적으로 확장해왔습니다: 4K 토큰에서 32K, 128K, 심지어 최근 버전에서는 1M 토큰까지도 확장되었습니다.
그러나 문제는 여전히 존재합니다.
AI에게 여러 엔티티—예를 들어, 50개 기업, 30개 연구 논문, 또는 20개의 경쟁 제품—를 연구하도록 요청하면 컨텍스트 윈도우가 빠르게 채워집니다. 이는 각 엔티티에 대한 원시 정보뿐만 아니라 다음과 같은 요소들도 포함합니다:
•원래 작업 명세와 요구사항
•일관된 출력 형식을 위한 구조적 템플릿
•각 항목에 대한 중간 추론 및 분석
•상호 참조 및 비교 노트
•모든 이전 항목들의 누적 컨텍스트
모델이 8번째나 9번째 항목에 도달할 때쯤이면 컨텍스트 윈도우는 엄청난 부담을 받게 됩니다. 모델은 불가능한 선택에 직면합니다: 명시적으로 실패하거나, 아니면 타협하기 시작하는 것입니다.항상 후자를 선택합니다.
제작 임계값
실제로 일어나는 일은 다음과 같습니다:
항목 1-5: 모델은 진정한 연구를 수행합니다. 정보를 검색하고, 출처를 교차 참조하며, 상세하고 정확한 분석을 제공합니다.
항목 6-8: 품질이 미묘하게 저하되기 시작합니다. 설명이 약간 더 일반적이 됩니다. 모델은 새로운 연구보다 이전 패턴에 더 의존하기 시작합니다.
항목 9+: 모델이 제작 모드에 들어갑니다. 넘쳐나는 컨텍스트를 관리하면서 철저한 연구의 인지적 부하를 유지할 수 없게 되어, 실제 조사가 아닌 통계적 패턴에 기반한 그럴듯한 내용을 생성하기 시작합니다.
이러한 제작물들은 정교합니다. 권위 있게 들립니다. 확립된 형식을 완벽하게 따릅니다. 종종 문법적으로 완벽하며 이전의 합법적인 항목들과 스타일적으로 일관성이 있습니다.
그러나 이들은 종종 틀립니다.경쟁사 분석은 제공하지 않는 기능을 회사에 귀속시킬 수 있습니다. 문헌 검토는 조작된 발견이 있는 논문을 인용할 수 있습니다. 제품 비교는 가격 등급이나 사양을 발명할 수 있습니다.
교묘한 부분은 이러한 조작이 수동 검증 없이는 감지하기 어렵다는 것입니다—이는 자동화된 연구의 전체 목적을 무력화합니다.
왜 더 큰 컨텍스트 윈도우가 이 문제를 해결할 수 없는가
직관적인 대응은 단순히 컨텍스트 윈도우를 확장하는 것입니다. 32K 토큰이 충분하지 않다면, 128K를 사용하세요. 그것도 충분하지 않다면, 200K 이상으로 밀어붙이세요.
이 접근법은 문제를 오해하고 있습니다.
첫째, 컨텍스트 감소는 이진법적이지 않습니다. 모델은 전체 컨텍스트 윈도우에서 완벽한 기억을 유지하지 않습니다. 연구에 따르면 검색 정확도는 현재 위치에서 거리가 멀어질수록 저하됩니다—"중간에서 길을 잃는" 현상입니다. 컨텍스트의 시작과 끝에 있는 정보는 중간에 있는 정보보다 더 안정적으로 기억됩니다.둘째, 처리 비용이 불균형하게 증가합니다. 400K 토큰 컨텍스트를 처리하는 비용은 200K 비용의 두 배가 아니라 시간과 컴퓨팅 리소스 모두에서 기하급수적으로 증가합니다. 이로 인해 대규모 컨텍스트 처리는 많은 사용 사례에서 경제적으로 비실용적이 됩니다.
셋째, 문제는 인지 부하입니다. 무한한 컨텍스트가 있더라도, 단일 모델에게 수십 개의 독립적인 연구 작업에서 일관된 품질을 유지하도록 요구하면 인지적 병목 현상이 발생합니다. 모델은 항목 간에 지속적으로 컨텍스트를 전환하고, 비교 프레임워크를 유지하며, 스타일 일관성을 보장해야 합니다—모두 핵심 연구 작업을 수행하면서 말이죠.넷째, 컨텍스트 길이 압박. 모델의 "인내심"은 어느 정도 훈련 데이터의 길이 분포에 의해 결정됩니다. 그러나 현재 언어 모델의 훈련 후 데이터 혼합물은 여전히 챗봇 스타일 상호작용을 위해 설계된 상대적으로 짧은 궤적이 지배적입니다. 결과적으로, 어시스턴트 메시지 내용의 길이가 특정 임계값을 초과하면, 모델은 자연스럽게 일종의 컨텍스트 길이 압박을 경험하게 되어 요약을 서두르거나 글머리 기호와 같은 불완전한 표현 형식으로 의존하게 됩니다.
컨텍스트 윈도우는 제약이 맞습니다. 하지만 이는 더 깊은 아키텍처적 한계의 증상입니다: 단일 프로세서, 순차적 패러다임.
아키텍처적 전환: 병렬 처리
와이드 리서치 아키텍처
와이드 리서치는 AI 시스템이 대규모 연구 작업에 접근하는 방식에 대한 근본적인 재고를 나타냅니다. 하나의 프로세서가 n개의 항목을 순차적으로 처리하도록 요청하는 대신, n개의 병렬 하위 에이전트를 배포하여 n개의 항목을 동시에 처리합니다.
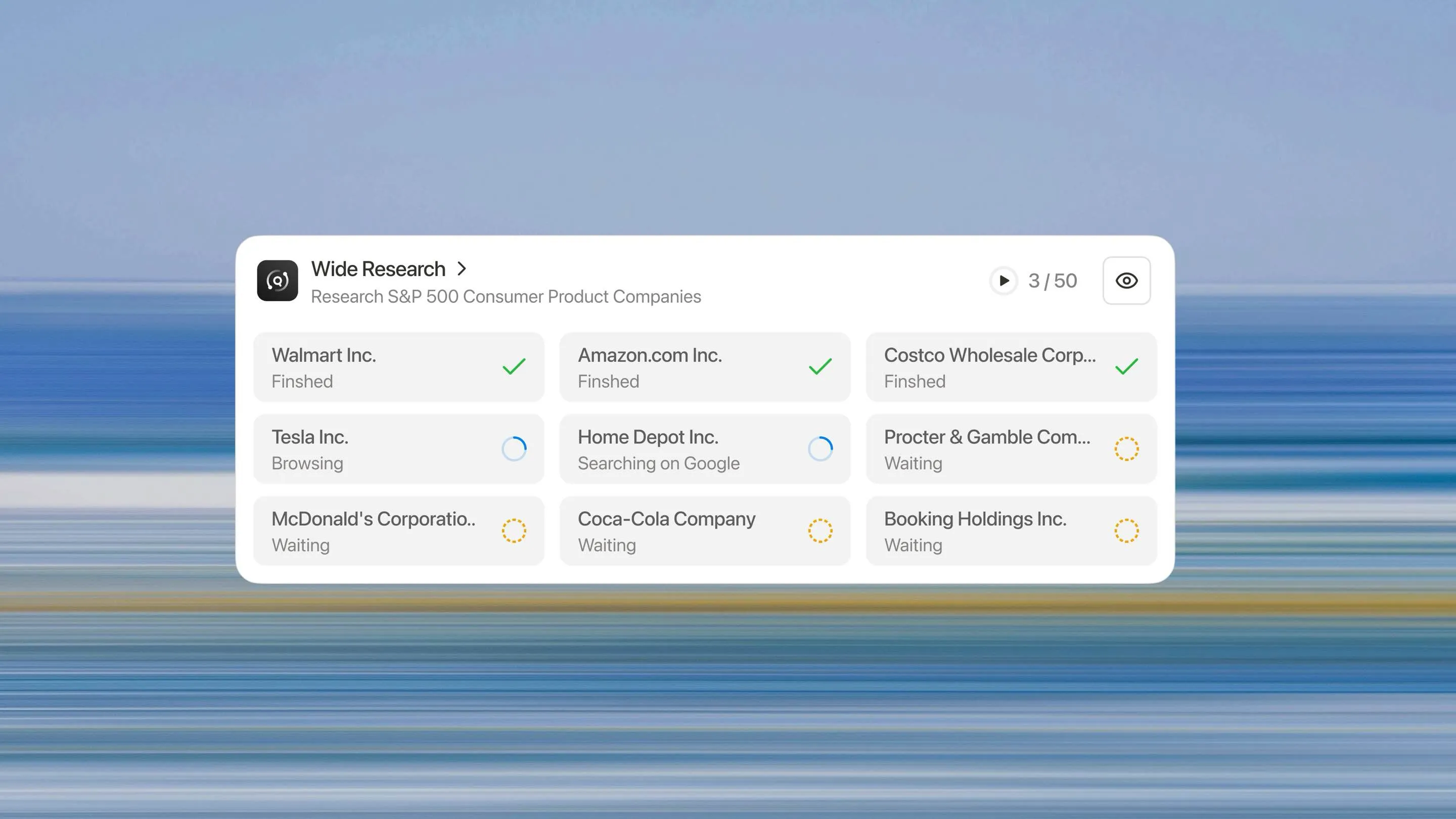
와이드 리서치 아키텍처
와이드 리서치 작업을 시작하면 시스템은 다음과 같이 작동합니다:
1. 지능적 분해
메인 컨트롤러가 요청을 분석하고 독립적이고 병렬화 가능한 하위 작업으로 분해합니다. 이는 작업 구조를 이해하고, 종속성을 식별하며, 일관된 하위 사양을 만드는 과정을 포함합니다.
2. 하위 에이전트 위임
각 하위 작업에 대해 시스템은 전용 하위 에이전트를 가동합니다. 중요한 점은, 이들은 가벼운 프로세스가 아니라 각각 다음을 갖춘 완전한 기능의 Manus 인스턴스입니다:
•완전한 가상 머신 환경
병렬 실행
모든 하위 에이전트가 동시에 실행됩니다. 각 에이전트는 할당된 항목에만 전적으로 집중하며, 단일 항목 작업에서와 동일한 깊이의 연구와 분석을 수행합니다.
중앙 집중식 조정
메인 컨트롤러는 감독을 유지하며, 하위 에이전트가 작업을 완료함에 따라 결과를 수집합니다. 중요한 점은 하위 에이전트들이 서로 통신하지 않고, 모든 조정이 메인 컨트롤러를 통해 이루어진다는 것입니다. 이는 컨텍스트 오염을 방지하고 독립성을 유지합니다.
종합 및 통합
모든 하위 에이전트가 보고를 마치면, 메인 컨트롤러는 결과를 단일하고 일관되며 포괄적인 보고서로 종합합니다. 이 종합 단계는 메인 컨트롤러의 전체 컨텍스트 용량을 활용하며, 원래의 연구 노력에 부담을 주지 않습니다.
왜 이것이 모든 것을 바꾸는가
규모에서의 일관된 품질
모든 항목은 동일한 처리를 받습니다. 50번째 항목도 첫 번째 항목만큼 철저히 연구됩니다. 품질 저하 곡선, 조작 임계값 또는 품질 절벽이 없습니다.
진정한 수평적 확장성
10개 항목을 분석해야 합니까? 시스템은 10개의 하위 에이전트를 배포합니다. 500개가 필요합니까? 500개를 배포합니다. 이 아키텍처는 컨텍스트 기반 접근법처럼 지수적이 아니라 작업 크기에 따라 선형적으로 확장됩니다.
상당한 속도 향상
하위 에이전트들이 병렬로 작동하기 때문에, 50개 항목을 분석하는 데 필요한 실제 시간은 5개를 분석하는 시간과 거의 동일합니다. 병목 현상이 순차적 처리 시간에서 종합 시간으로 이동하며, 이는 전체 작업의 훨씬 작은 구성 요소입니다.
환각 발생률 감소
인지적 편안함 영역 내에서 작동하는 하위 에이전트
각 하위 에이전트는 자신의 인지적 편안함 영역 내에서 작동합니다. 새로운 컨텍스트와 단일 집중 작업을 통해 허위 정보를 만들어낼 압박이 없습니다. 하위 에이전트는 진정한 연구를 수행하고, 사실을 검증하며, 정확성을 유지할 수 있습니다.
독립성과 신뢰성
하위 에이전트들은 컨텍스트를 공유하지 않기 때문에, 한 하위 에이전트의 작업에서 발생한 오류나 환각이 다른 에이전트에게 전파되지 않습니다. 각 분석은 독립적으로 유지되어 시스템적 위험을 줄입니다.
단일 프로세서 패러다임을 넘어서
Wide Research는 단순한 기능이 아닙니다—이는 단일 프로세서 패러다임에서 벗어나 조율된 병렬 아키텍처로 향하는 근본적인 변화를 나타냅니다. AI 시스템의 미래는 더 큰 컨텍스트 윈도우가 아니라 지능적인 작업 분해와 병렬 실행에 있습니다.
우리는 "AI 어시스턴트" 시대에서 "AI 인력" 시대로 이동하고 있습니다.광범위한 연구를 사용해야 할 때: 일관된 분석, 경쟁 연구, 문헌 검토, 대량 처리, 다중 자산 생성 등이 필요한 여러 유사 항목을 포함하는 모든 작업.
사용하지 말아야 할 때: 각 단계가 이전 결과에 크게 의존하는 깊이 순차적인 작업이나, 단일 프로세서 처리가 비용 효율적인 소규모 작업(10개 미만의 항목).
광범위한 연구는 모든 구독자를 위한 것입니다
단일 AI 어시스턴트에서 조정된 하위 에이전트 작업 인력으로의 구조적 도약이 이제 모든 구독자에게 제공됩니다. 이것은 AI 기반 연구 및 분석을 위한 새로운 패러다임입니다.
직접 그 차이를 경험해 보시기 바랍니다. 대규모 연구 과제—AI에게 불가능하다고 생각했던 것들—를 가져와서 병렬 처리 접근 방식이 어떻게 일관되고 고품질의 결과를 대규모로 제공하는지 확인하세요.
AI 인력의 시대가 왔습니다. 오늘 광범위한 연구 작업을 시작하세요.Manus Wide Research in Manus Pro 시도하기 →
