Wide Research: Oltre la Finestra di Contesto
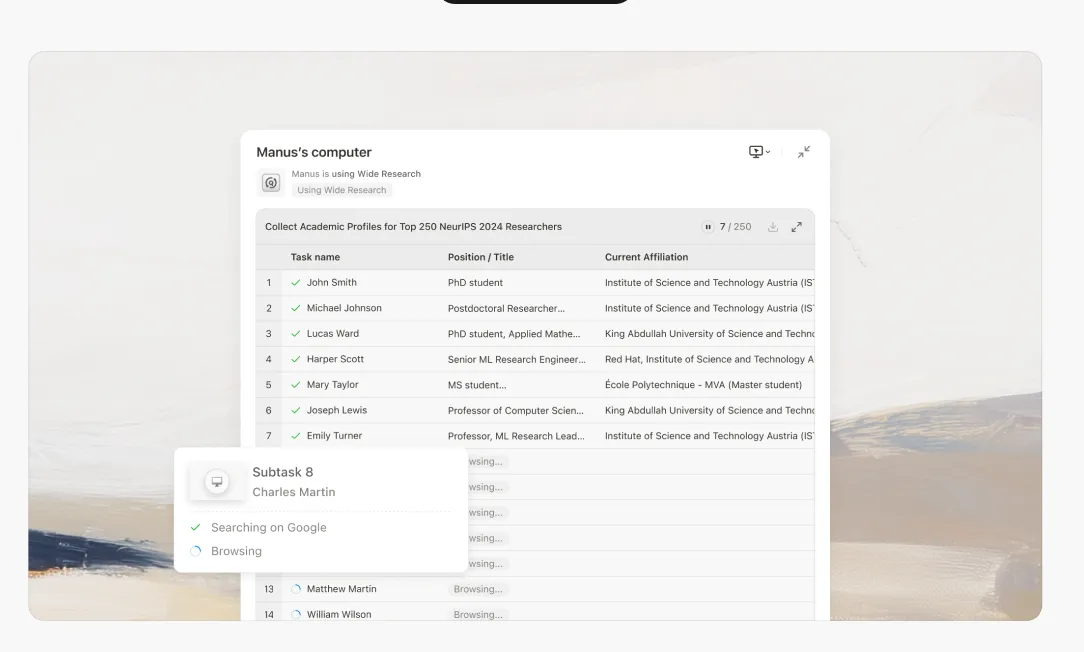
La promessa della ricerca guidata dall'IA è sempre stata convincente: delegare il noioso lavoro di raccolta e sintesi delle informazioni a un sistema intelligente, liberando la cognizione umana per l'analisi di ordine superiore e il processo decisionale. Tuttavia, chiunque abbia spinto questi sistemi su casi d'uso non banali si è scontrato con una realtà frustrante: all'ottavo o nono elemento di un'attività di ricerca multi-soggetto, l'IA inizia a inventare.
Non si tratta solo di semplificare. Non si tratta solo di riassumere in modo più conciso. Inventare.
Questo non è un problema di ingegneria dei prompt. Non è un problema di capacità del modello. È un vincolo architetturale che ha silenziosamente limitato l'utilità degli strumenti di ricerca basati sull'IA fin dalla loro nascita. Ed è il vincolo che Wide Research è progettato per superare.
La Finestra Contestuale: Un Collo di Bottiglia Fondamentale
Ogni modello linguistico di grandi dimensioni opera all'interno di una finestra di contesto, un buffer di memoria finito che limita la quantità di informazioni che il modello può elaborare attivamente in qualsiasi momento. I modelli moderni hanno spinto questo limite in modo impressionante: da 4K token a 32K, 128K, e persino 1M token nelle versioni più recenti.
Tuttavia il problema persiste.
Quando chiedi a un'IA di ricercare più entità - ad esempio, cinquanta aziende, trenta articoli di ricerca, o venti prodotti concorrenti - la finestra di contesto si riempie rapidamente. Non si tratta solo delle informazioni grezze su ciascuna entità, ma anche di:
•Le specifiche e i requisiti del compito originale
•Il modello strutturale per un formato di output coerente
•Ragionamento intermedio e analisi per ogni elemento
•Note di riferimento incrociato e comparative
•Il contesto cumulativo di tutti gli elementi precedenti
Nel momento in cui il modello raggiunge l'ottavo o il nono elemento, la finestra di contesto è sotto un'enorme pressione. Il modello si trova di fronte a una scelta impossibile: fallire esplicitamente o iniziare a tagliare gli angoli.Sceglie sempre quest'ultimo.
La Soglia di Fabbricazione
Ecco cosa accade nella pratica:
Elementi 1-5: Il modello esegue una ricerca genuina. Recupera informazioni, incrocia le fonti e produce un'analisi dettagliata e accurata.
Elementi 6-8: La qualità inizia a degradarsi sottilmente. Le descrizioni diventano leggermente più generiche. Il modello inizia a fare più affidamento su schemi precedenti che su una nuova ricerca.
Elementi 9+: Il modello entra in modalità di fabbricazione. Incapace di mantenere il carico cognitivo di una ricerca approfondita mentre gestisce un contesto traboccante, inizia a generare contenuti plausibili basati su schemi statistici, non su una reale investigazione.
Queste fabbricazioni sono sofisticate. Suonano autorevoli. Seguono perfettamente il formato stabilito. Sono spesso grammaticalmente impeccabili e stilisticamente coerenti con le voci precedenti, legittime.
Sono anche frequentemente sbagliate.Un'analisi della concorrenza potrebbe attribuire funzionalità ad aziende che non le offrono. Una revisione della letteratura potrebbe citare articoli con risultati inventati. Un confronto tra prodotti potrebbe inventare livelli di prezzo o specifiche.
La parte insidiosa è che queste invenzioni sono difficili da rilevare senza una verifica manuale—che vanifica l'intero scopo della ricerca automatizzata.
Perché Finestre di Contesto Più Grandi Non Possono Risolvere Questo Problema
La risposta intuitiva è semplicemente espandere la finestra di contesto. Se 32K token non sono sufficienti, usarne 128K. Se non bastano, spingere fino a 200K o oltre.
Questo approccio fraintende il problema.
Primo, il decadimento del contesto non è binario. Un modello non mantiene un richiamo perfetto attraverso l'intera finestra di contesto. Gli studi hanno dimostrato che la precisione del recupero si degrada con la distanza dalla posizione corrente—il fenomeno "perso nel mezzo". Le informazioni all'inizio e alla fine del contesto vengono richiamate in modo più affidabile rispetto alle informazioni nel mezzo.In secondo luogo, il costo di elaborazione cresce in modo sproporzionato. Il costo per elaborare un contesto di 400K token non è semplicemente il doppio del costo di 200K—aumenta esponenzialmente sia in termini di tempo che di risorse di calcolo. Questo rende l'elaborazione di contesti enormi economicamente impraticabile per molti casi d'uso.
In terzo luogo, il problema è il carico cognitivo. Anche con un contesto infinito, chiedere a un singolo modello di mantenere una qualità costante su decine di compiti di ricerca indipendenti crea un collo di bottiglia cognitivo. Il modello deve costantemente cambiare contesto tra gli elementi, mantenere un quadro comparativo e garantire coerenza stilistica—tutto mentre esegue il compito di ricerca principale.Quarto, pressione sulla lunghezza del contesto. La "pazienza" del modello è, in una certa misura, determinata dalla distribuzione della lunghezza dei campioni nei suoi dati di addestramento. Tuttavia, la miscela di dati post-addestramento dei modelli linguistici attuali è ancora dominata da traiettorie relativamente brevi progettate per interazioni in stile chatbot. Di conseguenza, quando la lunghezza del contenuto di un messaggio dell'assistente supera una certa soglia, il modello naturalmente sperimenta una sorta di pressione sulla lunghezza del contesto, spingendolo ad affrettarsi verso la sintesi o a ricorrere a forme di espressione incomplete come elenchi puntati.
La finestra di contesto è un vincolo, sì. Ma è un sintomo di una limitazione architettonica più profonda: il paradigma sequenziale a processore singolo.
Il Cambiamento Architettonico: Elaborazione Parallela
L'Architettura Wide Research
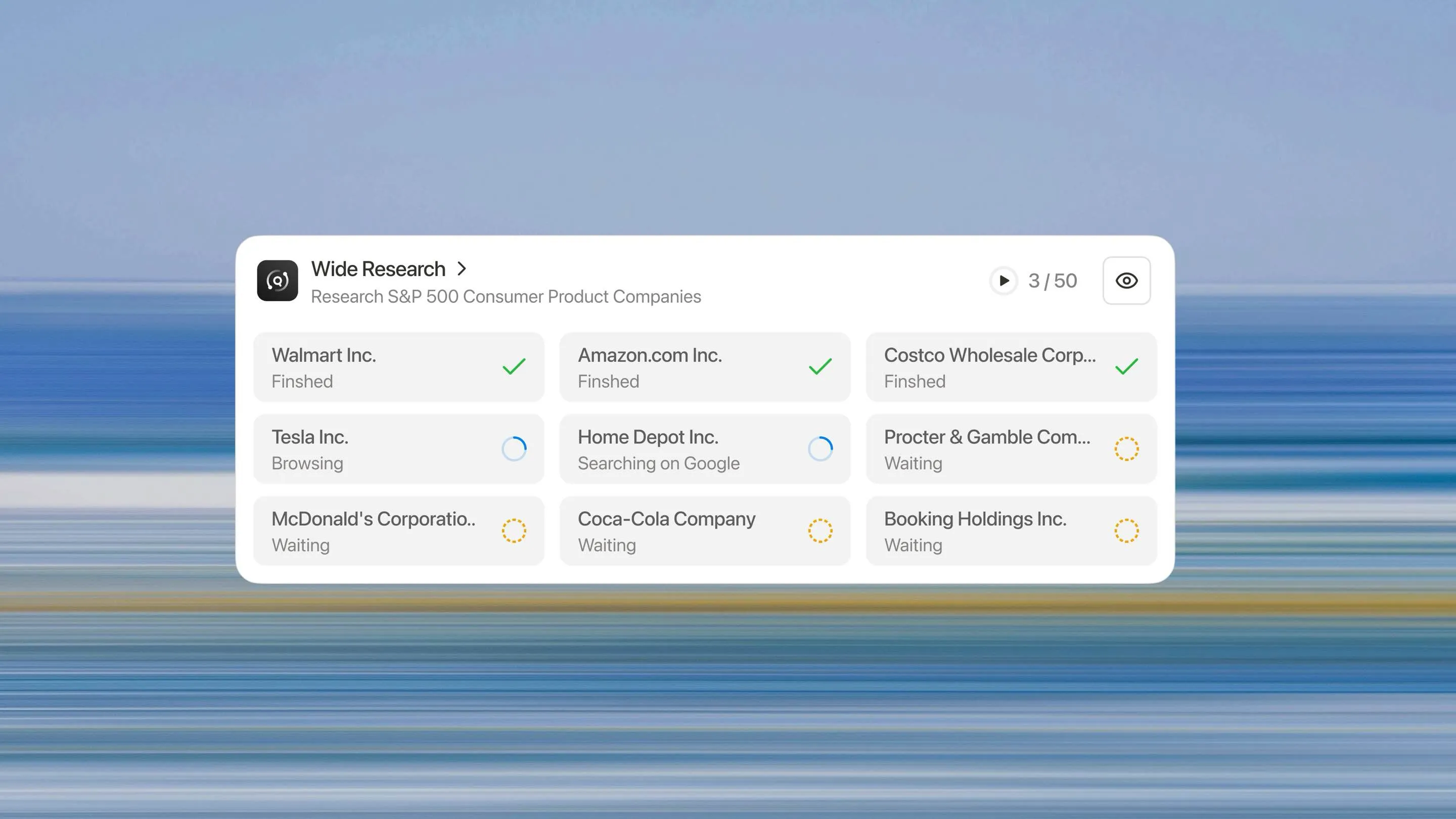
Wide Research rappresenta un ripensamento fondamentale di come un sistema di IA dovrebbe affrontare attività di ricerca su larga scala. Invece di chiedere a un singolo processore di gestire n elementi sequenzialmente, impieghiamo n sub-agenti paralleli per elaborare n elementi simultaneamente.
L'Architettura Wide Research
Quando avvii un'attività di Wide Research, il sistema opera come segue:
1. Decomposizione Intelligente
Il controller principale analizza la tua richiesta e la suddivide in sotto-attività indipendenti e parallelizzabili. Questo comporta la comprensione della struttura dell'attività, l'identificazione delle dipendenze e la creazione di sotto-specifiche coerenti.
2. Delegazione ai Sub-agenti
Per ogni sotto-attività, il sistema avvia un sub-agente dedicato. È fondamentale notare che questi non sono processi leggeri, ma istanze Manus complete, ciascuna con:
•Un ambiente di macchina virtuale completo
Esecuzione Parallela
Tutti i sub-agent vengono eseguiti contemporaneamente. Ognuno si concentra esclusivamente sul proprio elemento assegnato, eseguendo la stessa profondità di ricerca e analisi che farebbe per un'attività a elemento singolo.
Coordinamento Centralizzato
Il controller principale mantiene la supervisione, raccogliendo i risultati man mano che i sub-agent completano i loro compiti. È importante notare che i sub-agent non comunicano tra loro, tutto il coordinamento passa attraverso il controller principale. Questo previene la contaminazione del contesto e mantiene l'indipendenza.
Sintesi e Integrazione
Una volta che tutti i sub-agent hanno riferito, il controller principale sintetizza i risultati in un unico rapporto coerente e completo. Questa fase di sintesi sfrutta la piena capacità di contesto del controller principale, poiché non è gravato dallo sforzo di ricerca originale.
Perché Questo Cambia Tutto
Qualità Costante su Larga Scala
Ogni elemento riceve lo stesso trattamento. Il 50° elemento viene ricercato con la stessa accuratezza del primo. Non c'è curva di degradazione, nessuna soglia di fabbricazione e nessun calo di qualità.
Vera Scalabilità Orizzontale
Bisogno di analizzare 10 elementi? Il sistema distribuisce 10 sub-agenti. Bisogno di analizzarne 500? Ne distribuisce 500. L'architettura si scala linearmente con la dimensione del compito, non esponenzialmente come gli approcci basati sul contesto.
Significativo Aumento di Velocità
Poiché i sub-agenti operano in parallelo, il tempo reale necessario per analizzare 50 elementi è all'incirca lo stesso di quello necessario per analizzarne 5. Il collo di bottiglia si sposta dal tempo di elaborazione sequenziale al tempo di sintesi—una componente molto più piccola del compito complessivo.
Riduzione del Tasso di Allucinazione
Indipendenza e affidabilità
Ogni sub-agente opera all'interno della propria zona di comfort cognitivo. Con un contesto nuovo e un compito singolo e focalizzato, non c'è pressione per inventare. Il sub-agente può eseguire ricerche genuine, verificare fatti e mantenere l'accuratezza.
Indipendenza e affidabilità
Poiché i sub-agenti non condividono il contesto, un errore o un'allucinazione nel lavoro di un sub-agente non si propaga agli altri. Ogni analisi si regge da sola, riducendo il rischio sistemico.
Oltre il paradigma del singolo processore
Wide Research è più di una funzionalità: rappresenta un cambiamento fondamentale che si allontana dal paradigma del singolo processore verso un'architettura orchestrata e parallela. Il futuro dei sistemi di IA non risiede in finestre di contesto sempre più ampie, ma nella decomposizione intelligente dei compiti e nell'esecuzione parallela.
Stiamo passando dall'era dell'"assistente IA" all'era della "forza lavoro IA".Quando utilizzare la Ricerca Ampia: Qualsiasi attività che coinvolge elementi multipli e simili che richiedono un'analisi coerente: ricerche competitive, revisioni della letteratura, elaborazione in blocco, generazione di più asset.
Quando non utilizzarla: Attività profondamente sequenziali in cui ogni passaggio dipende fortemente dal risultato precedente, o piccole attività (meno di 10 elementi) dove la gestione a singolo processore è più conveniente.
La Ricerca Ampia è per tutti gli abbonati
Il salto architettonico da un singolo assistente AI a una forza lavoro coordinata di sub-agenti è ora disponibile per tutti gli abbonati. Questo è un nuovo paradigma per la ricerca e l'analisi basate sull'intelligenza artificiale.
Ti invitiamo a sperimentare la differenza in prima persona. Porta le tue sfide di ricerca su larga scala—quelle che pensavi fossero impossibili per l'AI—e osserva come un approccio di elaborazione parallela fornisce risultati coerenti e di alta qualità su scala.
L'era della forza lavoro AI è qui. Inizia oggi la tua attività di Ricerca Ampia.Prova Manus Wide Research in Manus Pro →
