Wide Research: Jenseits des Kontextfensters
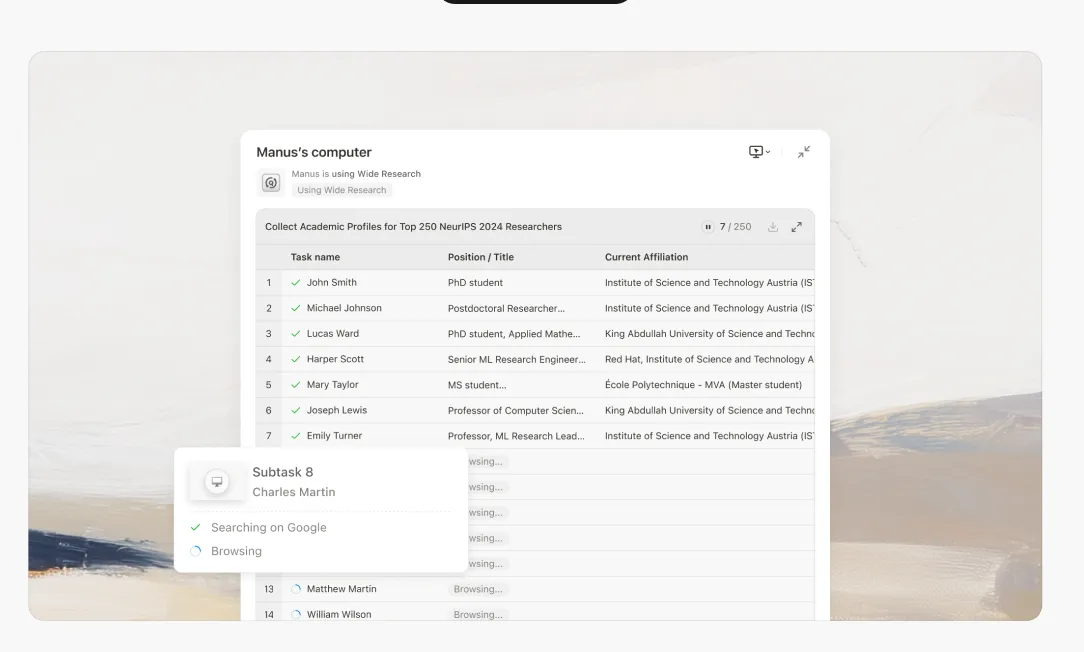
Das Versprechen der KI-gestützten Forschung war immer überzeugend: Delegiere die mühsame Arbeit der Informationsbeschaffung und -synthese an ein intelligentes System und befreie das menschliche Denken für höherwertige Analysen und Entscheidungsfindung. Dennoch ist jeder, der diese Systeme bei nicht-trivialen Anwendungsfällen eingesetzt hat, auf eine frustrierende Realität gestoßen: beim achten oder neunten Element einer Forschungsaufgabe mit mehreren Themen beginnt die KI zu fabulieren.
Nicht nur zu vereinfachen. Nicht nur prägnanter zusammenzufassen. Zu fabulieren.
Dies ist kein Problem des Prompt-Engineerings. Es ist kein Problem der Modellkapazität. Es ist eine architektonische Einschränkung, die den Nutzen von KI-Forschungstools seit ihrer Entstehung leise begrenzt hat. Und es ist die Einschränkung, die Wide Research überwinden soll.
Das Kontextfenster: Ein fundamentaler Engpass
Jedes große Sprachmodell arbeitet innerhalb eines Kontextfensters, eines begrenzten Speicherpuffers, der die Menge an Informationen begrenzt, die das Modell zu jedem Zeitpunkt aktiv verarbeiten kann. Moderne Modelle haben diese Grenze beeindruckend erweitert: von 4K Tokens auf 32K, 128K und sogar 1M Tokens in neueren Versionen.
Dennoch besteht das Problem weiterhin.
Wenn Sie eine KI bitten, mehrere Entitäten zu recherchieren - beispielsweise fünfzig Unternehmen, dreißig Forschungsarbeiten oder zwanzig konkurrierende Produkte - füllt sich das Kontextfenster schnell. Es sind nicht nur die Rohinformationen zu jeder Entität, sondern auch:
•Die ursprüngliche Aufgabenstellung und Anforderungen
•Die strukturelle Vorlage für konsistente Ausgabeformatierung
•Zwischenüberlegungen und Analysen für jeden Punkt
•Querverweise und vergleichende Notizen
•Der kumulative Kontext aller vorhergehenden Elemente
Wenn das Modell das achte oder neunte Element erreicht, steht das Kontextfenster unter enormem Druck. Das Modell steht vor einer unmöglichen Wahl: explizit scheitern oder anfangen, Abkürzungen zu nehmen.Es entscheidet sich immer für Letzteres.
Die Schwelle der Fabrikation
So läuft es in der Praxis ab:
Punkte 1-5: Das Modell führt echte Recherchen durch. Es ruft Informationen ab, vergleicht Quellen und erstellt detaillierte, genaue Analysen.
Punkte 6-8: Die Qualität beginnt sich subtil zu verschlechtern. Beschreibungen werden etwas allgemeiner. Das Modell beginnt, sich mehr auf frühere Muster als auf neue Recherchen zu verlassen.
Punkte 9+: Das Modell wechselt in den Fabrikationsmodus. Da es nicht in der Lage ist, die kognitive Belastung gründlicher Recherche aufrechtzuerhalten, während es einen überlaufenden Kontext verwaltet, beginnt es, plausibel klingende Inhalte auf der Grundlage statistischer Muster zu generieren, nicht auf der Grundlage tatsächlicher Untersuchungen.
Diese Fabrikationen sind anspruchsvoll. Sie klingen autoritativ. Sie folgen dem etablierten Format perfekt. Sie sind oft grammatikalisch einwandfrei und stilistisch konsistent mit den früheren, legitimen Einträgen.
Sie sind auch häufig falsch.Eine Wettbewerbsanalyse könnte Unternehmen Funktionen zuschreiben, die sie nicht anbieten. Eine Literaturübersicht könnte Arbeiten mit erfundenen Ergebnissen zitieren. Ein Produktvergleich könnte Preisstufen oder Spezifikationen erfinden.
Das Heimtückische daran ist, dass diese Erfindungen ohne manuelle Überprüfung schwer zu erkennen sind—was den gesamten Zweck der automatisierten Recherche zunichtemacht.
Warum größere Kontextfenster dieses Problem nicht lösen können
Die intuitive Antwort ist, einfach das Kontextfenster zu erweitern. Wenn 32K Token nicht ausreichen, verwende 128K. Wenn das nicht ausreicht, erhöhe auf 200K oder mehr.
Dieser Ansatz versteht das Problem falsch.
Erstens, Kontextverfall ist nicht binär. Ein Modell behält nicht die perfekte Erinnerung über sein gesamtes Kontextfenster. Studien haben gezeigt, dass die Abrufgenauigkeit mit dem Abstand von der aktuellen Position abnimmt—das "in der Mitte verloren" Phänomen. Informationen am Anfang und Ende des Kontexts werden zuverlässiger erinnert als Informationen in der Mitte.Zweitens, die Verarbeitungskosten steigen unverhältnismäßig an. Die Kosten für die Verarbeitung eines 400K-Token-Kontexts sind nicht nur doppelt so hoch wie die eines 200K-Kontexts—sie steigen exponentiell sowohl in Zeit als auch in Rechenressourcen. Dies macht die Verarbeitung massiver Kontexte für viele Anwendungsfälle wirtschaftlich unpraktisch.
Drittens, das Problem ist die kognitive Belastung. Selbst mit einem unendlichen Kontext erzeugt die Anforderung an ein einzelnes Modell, eine konsistente Qualität über Dutzende unabhängiger Forschungsaufgaben hinweg aufrechtzuerhalten, einen kognitiven Engpass. Das Modell muss ständig den Kontext zwischen Elementen wechseln, einen vergleichenden Rahmen beibehalten und stilistische Konsistenz sicherstellen—all das während es die Kernforschungsaufgabe ausführt.Viertens, Kontextlängendruck. Die "Geduld" des Modells wird in gewissem Maße durch die Längenverteilung der Stichproben in seinen Trainingsdaten bestimmt. Die Mischung der Nachtrainingsdaten aktueller Sprachmodelle wird jedoch immer noch von relativ kurzen Trajektorien dominiert, die für Chatbot-artige Interaktionen konzipiert sind. Wenn die Länge des Inhalts einer Assistentennachricht einen bestimmten Schwellenwert überschreitet, erfährt das Modell daher natürlich eine Art Kontextlängendruck, der es dazu veranlasst, schneller zusammenzufassen oder auf unvollständige Ausdrucksformen wie Aufzählungspunkte zurückzugreifen.
Das Kontextfenster ist zwar eine Einschränkung. Aber es ist ein Symptom einer tieferen architektonischen Begrenzung: des Einzelprozessor-Sequenzparadigmas.
Die architektonische Verschiebung: Parallele Verarbeitung
Die Wide-Research-Architektur
Wide Research stellt ein grundlegendes Umdenken dar, wie ein KI-System große Rechercheaufgaben angehen sollte. Anstatt einen Prozessor zu bitten, n Elemente sequentiell zu verarbeiten, setzen wir n parallele Unteragenten ein, um n Elemente gleichzeitig zu verarbeiten.
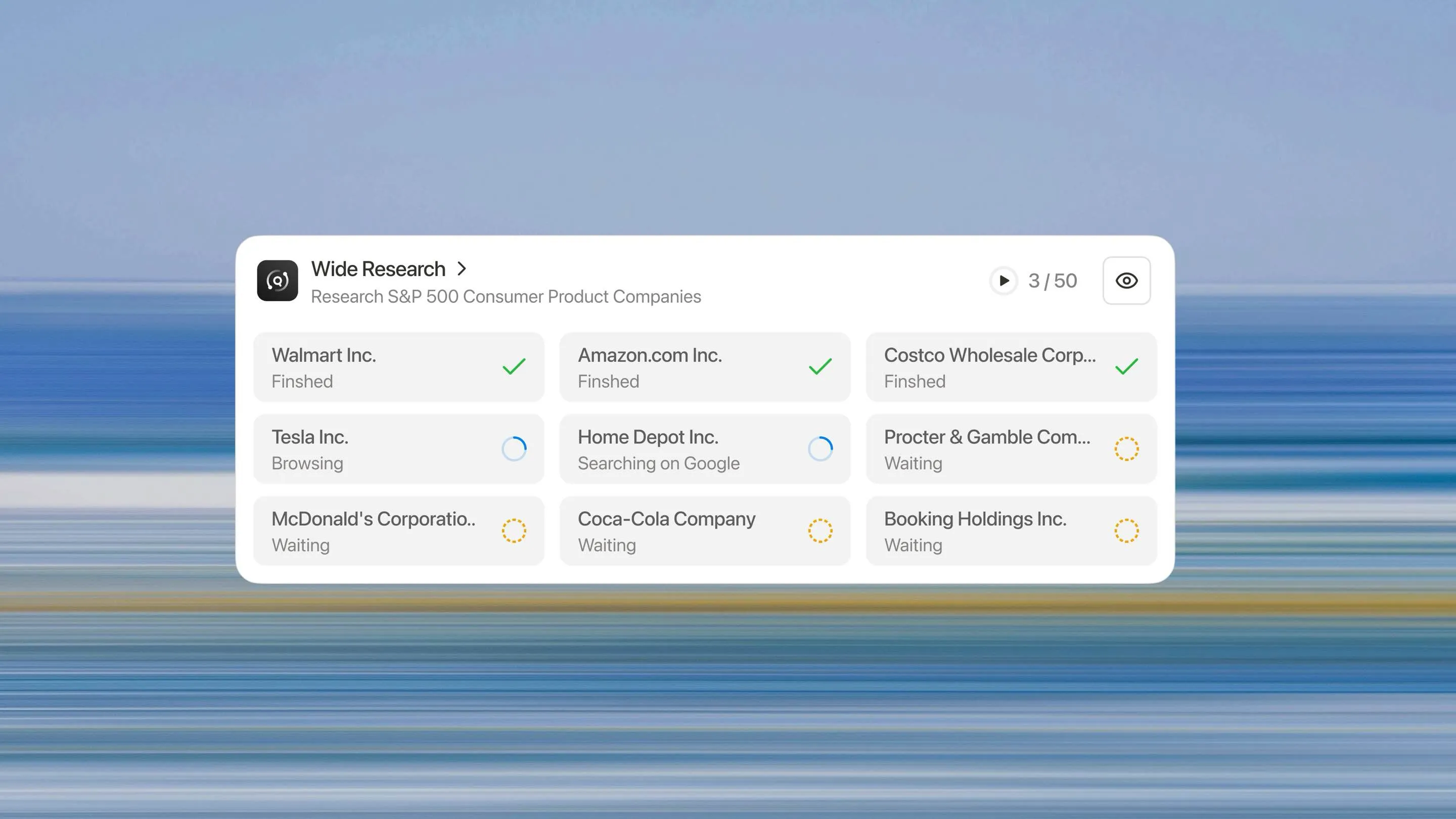
Die Wide-Research-Architektur
Wenn Sie eine Wide-Research-Aufgabe starten, funktioniert das System wie folgt:
1. Intelligente Zerlegung
Der Hauptcontroller analysiert Ihre Anfrage und zerlegt sie in unabhängige, parallelisierbare Teilaufgaben. Dies beinhaltet das Verstehen der Aufgabenstruktur, das Identifizieren von Abhängigkeiten und das Erstellen kohärenter Teilspezifikationen.
2. Delegation an Unteragenten
Für jede Teilaufgabe startet das System einen dedizierten Unteragenten. Entscheidend ist, dass es sich hierbei nicht um leichtgewichtige Prozesse handelt – es sind vollwertige Manus-Instanzen, jede mit:
•Einer kompletten virtuellen Maschinenumgebung
Parallele Ausführung
Alle Unter-Agenten werden gleichzeitig ausgeführt. Jeder konzentriert sich ausschließlich auf sein zugewiesenes Element und führt die gleiche Tiefe an Recherche und Analyse durch, die er für eine Einzelaufgabe durchführen würde.
Zentralisierte Koordination
Der Hauptcontroller behält die Aufsicht und sammelt die Ergebnisse, sobald die Unter-Agenten ihre Aufgaben abgeschlossen haben. Wichtig ist, dass die Unter-Agenten nicht miteinander kommunizieren, alle Koordination läuft über den Hauptcontroller. Dies verhindert Kontextverschmutzung und erhält die Unabhängigkeit.
Synthese und Integration
Sobald alle Unter-Agenten ihre Berichte abgeliefert haben, synthetisiert der Hauptcontroller die Ergebnisse zu einem einzigen, kohärenten und umfassenden Bericht. Dieser Syntheseschritt nutzt die volle Kontextkapazität des Hauptcontrollers, da er nicht mit dem ursprünglichen Rechercheaufwand belastet ist.
Warum das alles verändert
Konsistente Qualität im großen Maßstab
Jedes Element erhält die gleiche Behandlung. Das 50. Element wird genauso gründlich recherchiert wie das erste. Es gibt keine Qualitätsabnahme, keine Erfindungsschwelle und keinen Qualitätsabfall.
Echte horizontale Skalierbarkeit
Müssen 10 Elemente analysiert werden? Das System setzt 10 Sub-Agenten ein. 500 Elemente? Es setzt 500 ein. Die Architektur skaliert linear mit der Größe der Aufgabe, nicht exponentiell wie bei kontextbasierten Ansätzen.
Erhebliche Beschleunigung
Da die Sub-Agenten parallel arbeiten, ist die reale Zeit, die für die Analyse von 50 Elementen benötigt wird, ungefähr die gleiche wie für die Analyse von 5. Der Engpass verlagert sich von der sequentiellen Verarbeitungszeit zur Synthesezeit—einer viel kleineren Komponente der Gesamtaufgabe.
Reduzierte Halluzinationsrate
Unabhängigkeit und Zuverlässigkeit
Da die Unteragenten keinen Kontext teilen, breitet sich ein Fehler oder eine Halluzination in der Arbeit eines Unteragenten nicht auf die anderen aus. Jede Analyse steht für sich, was das systemische Risiko reduziert.
Jenseits des Einzelprozessor-Paradigmas
Wide Research ist mehr als nur eine Funktion - es repräsentiert eine fundamentale Abkehr vom Einzelprozessor-Paradigma hin zu einer orchestrierten, parallelen Architektur. Die Zukunft von KI-Systemen liegt nicht in immer größeren Kontextfenstern, sondern in intelligenter Aufgabenzerlegung und paralleler Ausführung.
Wir bewegen uns von der Ära des "KI-Assistenten" zur Ära der "KI-Belegschaft".Wann man Wide Research einsetzen sollte: Jede Aufgabe, die mehrere, ähnliche Elemente umfasst, die eine konsistente Analyse erfordern - Wettbewerbsforschung, Literaturrecherchen, Massendatenverarbeitung, Erstellung mehrerer Assets.
Wann man es nicht einsetzen sollte: Stark sequentielle Aufgaben, bei denen jeder Schritt stark vom vorherigen Ergebnis abhängt, oder kleine Aufgaben (weniger als 10 Elemente), bei denen die Bearbeitung durch einen einzelnen Prozessor kosteneffizienter ist.
Wide Research steht allen Abonnenten zur Verfügung
Der architektonische Sprung von einem einzelnen KI-Assistenten zu einer koordinierten Belegschaft von Unteragenten steht nun allen Abonnenten zur Verfügung. Dies ist ein neues Paradigma für KI-gestützte Forschung und Analyse.
Wir laden Sie ein, den Unterschied selbst zu erleben. Bringen Sie Ihre großangelegten Forschungsherausforderungen mit – die, von denen Sie dachten, sie seien für KI unmöglich – und erleben Sie, wie ein Parallelverarbeitungsansatz konsistente, qualitativ hochwertige Ergebnisse im großen Maßstab liefert.
Die Ära der KI-Belegschaft ist da. Starten Sie noch heute Ihre Wide Research-Aufgabe.Manus Wide Research in Manus Pro ausprobieren →
